
Linux の
uniq
コマンドは、テキスト ファイルを調べて一意の行または重複する行を探します。このガイドでは、その多用途性と機能に加えて、この気の利いたユーティリティを最大限に活用する方法について説明します。
Linux で一致するテキスト行を検索する
uniq
コマンドは
高速かつ柔軟で、優れた機能を備えています
。ただし、多くの Linux コマンドと同様、このコマンドにもいくつかの癖があります。それについて知っていれば問題ありません。内部関係者のノウハウを少しも持たずに思い切って行動を起こすと、その結果に頭を悩ませることになるかもしれません。作業を進めながら、これらの癖を指摘していきます。
uniq
コマンドは、ひたむきで、1 つのことをやり遂げることを目標にしている人に最適です。そのため
、パイプを操作し
、コマンド パイプラインで役割を果たすのにも特に適しています。
uniq
作業対象となる入力をソートする必要があるため、
最も頻繁に共同作業するツール
の 1 つは
sort
です。
点火しましょう!
オプションなしで uniq を実行する
ロバート ジョンソンの
曲
「I Believe I’ll Dust My Broom」
の歌詞を含むテキスト ファイルがあります。
uniq
何を意味するのか見てみましょう。
次のように入力して、出力を
less
にパイプします。
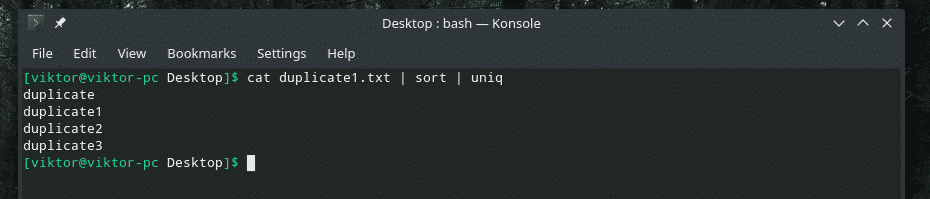
ユニークなダスト-マイ-ブルーム.txt |少ない
重複行を含む曲全体を
less
で取得します。
それは一意の行でも重複した行でもないようです。
そう、これが最初の癖だからです。オプションを指定せずに
uniq
を実行すると、
-u
(一意の行) オプションを使用したかのように動作します。これにより、ファイルから一意の行のみを出力するように
uniq
指示されます。重複した行が表示される理由は、
uniq
が行を重複とみなすには、その行がその重複に隣接している必要があり、ここで
sort
登場します。
ファイルを並べ替えると、重複した行がグループ化され、
uniq
それらを重複として扱います。ファイルに対して
sort
を使用し、ソートされた出力を
uniq
にパイプし、最終出力を
less
にパイプします。
これを行うには、次のように入力します。
ダスト-マイ-ブルーム.txt を並べ替える |ユニーク |少ない
ソートされた行のリストが
less
に表示されます。
「ほうきのほこりを払うと信じている」というラインは、この曲の中で間違いなく複数回登場します。実際、曲の最初の 4 行内でこれが 2 回繰り返されます。
では、なぜそれが固有の行のリストに表示されるのでしょうか?ファイル内に最初に出現する行は一意であるためです。後続のエントリのみが重複します。これは、一意の各行の最初の出現をリストすると考えることができます。
もう一度
sort
使用して、出力を新しいファイルにリダイレクトしてみましょう。こうすることで、すべてのコマンドで
sort
を使用する必要がなくなります。
次のコマンドを入力します。
ソート ダスト-マイ-ブルーム.txt > ソート.txt
これで、作業するための事前に並べ替えられたファイルができました。
重複を数える
-c
(カウント) オプションを使用すると、ファイル内に各行が出現する回数を出力できます。
次のコマンドを入力します。
uniq -c ソート済み.txt |少ない
各行は、ファイル内でその行が出現する回数で始まります。ただし、最初の行が空白であることがわかります。これは、ファイル内に 5 つの空白行があることがわかります。
出力を数値順にソートしたい場合は、
uniq
からの出力を
sort
にフィードできます。この例では、
-r
(逆引き) オプションと
-n
(数値並べ替え) オプションを使用し、結果を
less
にパイプします。
次のように入力します。
uniq -c ソート済み.txt |ソート -rn |少ない
リストは、各行の出現頻度に基づいて降順に並べ替えられます。

重複行のみをリストする
ファイル内で繰り返されている行のみを表示したい場合は、
-d
(繰り返し) オプションを使用できます。ファイル内で行が何回重複しても、リストされるのは 1 回だけです。
このオプションを使用するには、次のように入力します。
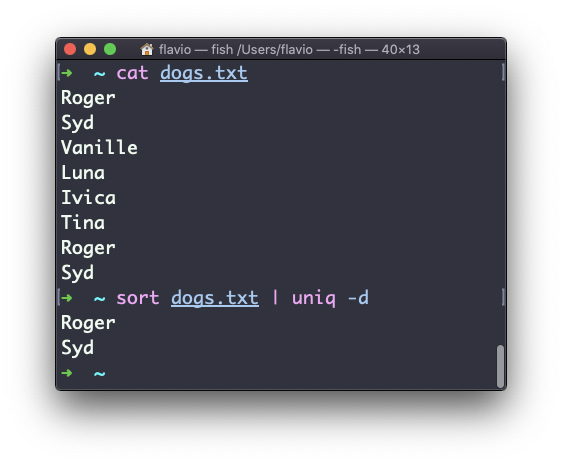
uniq -d ソート.txt
重複した行がリストに表示されます。先頭に空行があることに気づくでしょう。これは、ファイルに重複した空行が含まれていることを意味します。これは、リストを表面的にオフセットするために
uniq
によって残されたスペースではありません。
-d
(繰り返し) オプションと
-c
(カウント) オプションを組み合わせて、出力を
sort
にパイプすることもできます。これにより、少なくとも 2 回出現する行のソートされたリストが得られます。
このオプションを使用するには、次のように入力します。
uniq -d -c ソート済み.txt |ソート -rn
重複した行をすべてリストする
重複したすべての行のリストと、ファイル内に出現する行ごとのエントリを表示したい場合は、
-D
(すべての重複行) オプションを使用できます。
このオプションを使用するには、次のように入力します。
uniq -D ソート済み.txt |少ない
リストには、重複した各行のエントリが含まれます。
--group
オプションを使用すると、各グループの前 (
prepend
) または後 (
append
)、または各グループの前後両方 (
both
) に空行を入れた重複行がすべて出力されます。
修飾子として
append
使用しているので、次のように入力します。
uniq --group=sorted.txt を追加 |少ない
グループは読みやすくするために空行で区切られています。
一定の文字数を確認する
デフォルトでは、
uniq
各行の全体の長さをチェックします。ただし、チェックを特定の文字数に制限したい場合は、
-w
(文字チェック) オプションを使用できます。
この例では、最後のコマンドを繰り返しますが、比較は最初の 3 文字に限定されます。これを行うには、次のコマンドを入力します。
uniq -w 3 --group=sorted.txt を追加 |少ない
私たちが受け取る結果とグループ分けはまったく異なります。
「I b」で始まるすべての行は、行のそれらの部分が同一であるためグループ化され、重複とみなされます。
同様に、テキストの残りの部分が異なっていても、「I’m」で始まるすべての行は重複として扱われます。

一定数の文字を無視する
ファイル内の行に番号が付けられている場合など、各行の先頭で特定の数の文字をスキップした方が有益な場合があります。または、タイムスタンプを飛び越えて、最初の文字からではなく 6 文字目から行のチェックを開始するには、
uniq
が必要だとします。
以下は、行番号が付けられたソート済みファイルのバージョンです。
uniq
文字 3 から比較チェックを開始するようにしたい場合は、次のように入力して
-s
(文字をスキップ) オプションを使用できます。
uniq -s 3 -d -c 番号付き.txt
行は重複として検出され、正しくカウントされます。表示される行番号は、各重複が最初に出現した行番号であることに注意してください。
文字の代わりにフィールド (一連の文字と一部の空白) をスキップすることもできます。
-f
(フィールド) オプションを使用して、どのフィールドを無視するかを
uniq
指示します。
次のように入力して、
uniq
に最初のフィールドを無視するように指示します。
uniq -f 1 -d -c 番号付き.txt
各行の先頭で 3 文字をスキップするように
uniq
指示したときと同じ結果が得られます。
大文字と小文字を区別しない
デフォルトでは、
uniq
では大文字と小文字が区別されます。同じ文字が大文字で小文字で表示される場合、
uniq
その行が異なるものであるとみなします。
たとえば、次のコマンドの出力を確認してください。
uniq -d -c ソート済み.txt |ソート -rn
「私はほうきの粉を払うと信じています」と「ほうきの粉を払うと信じています」という行は、「believe」の「B」の大文字と小文字が異なるため、重複として扱われません。
ただし、
-i
(大文字と小文字を無視する) オプションを含めると、これらの行は重複として扱われます。次のように入力します。
uniq -d -c -i ソート済み.txt |ソート -rn
行は重複として扱われ、グループ化されるようになりました。
Linux では、多数の特別なユーティリティを自由に使用できます。多くのツールと同様に、
uniq
毎日使用するツールではありません。
そのため、Linux に習熟するには、どのツールが現在の問題を解決してくれるのか、またその問題をどこで見つけられるのかを覚えておくことが重要です。ただし、練習すれば、うまくいくでしょう。
または、いつでも を検索することもできます。おそらくそれに関する記事があるでしょう。
関連: 開発者と愛好家のための最高の Linux ラップトップ




