
重要なポイント
- Linux sed コマンドは、インターフェイスのない強力なテキスト エディターであり、ファイルやストリーム内のテキストを操作するために使用されます。
- Sed は、ファイルやストリーム内のテキストを選択、置換、追加、削除、変更することができ、動作時に従うべき指示を提供します。
- Sed はパターン マッチングとテキスト選択で正規表現に大きく依存しており、sed を効果的に使用するには正規表現に精通していることが重要です。
クレイジーに聞こえるかもしれませんが、Linux の
sed
コマンドはインターフェイスのないテキスト エディターです。コマンド ラインからこれを使用して、ファイルやストリーム内のテキストを操作できます。その力を活用する方法を紹介します。
sedの力
sed
コマンドはチェスに似ています。基本を学ぶには 1 時間かかりますが、それをマスターするには一生かかります (または、少なくともかなりの練習が必要です)。
sed
機能の主要なカテゴリごとに、序盤のガンビットをいくつか紹介します。
sed
は、パイプされた入力またはテキスト ファイルを処理する
ストリーム エディター
です。ただし、対話型のテキスト エディター インターフェイスはありません。むしろ、テキストを読み進める際に従うべき指示を提供します。これはすべて、Bash およびその他のコマンドライン シェルで機能します。
sed
使用すると、次のすべてを行うことができます。
- テキストを選択
- 代替テキスト
- テキストに行を追加する
- テキストから行を削除する
- 元のファイルを変更(または保存)する
最も簡潔な (そして最もとっつきにくい)
sed
コマンドを作成するためではなく、概念を紹介および実証するために例を構成しました。ただし、
sed
のパターン マッチングおよびテキスト選択機能は、正規表現 (
regexes
) に大きく依存しています。
sed
を最大限に活用するには、これらについてある程度の知識が必要です。

簡単な例
まず、
echo
を使用して、
パイプ経由で
テキストを
sed
に送信し、テキストの一部を
sed
に置き換えます。これを行うには、次のように入力します。
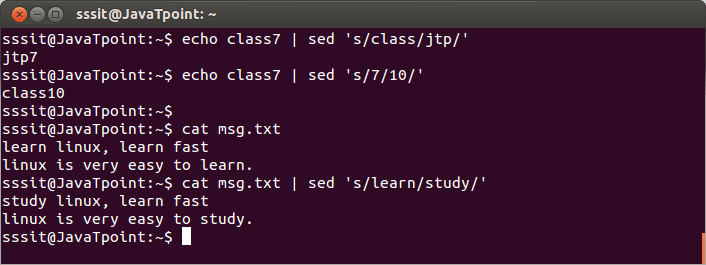
エコーハウツーゴンク | sed 's/gonk/geek/'
echo
コマンドは「howtogonk」を
sed
に送信し、単純な置換ルール (「s」は置換を表します) が適用されます。
sed
、入力テキスト内で最初の文字列が出現するかどうかを検索し、一致した文字列を 2 番目の文字列に置き換えます。
文字列「gonk」は「geek」に置き換えられ、新しい文字列が端末ウィンドウに表示されます。
置換はおそらく
sed
の最も一般的な使用法です。ただし、置換について詳しく説明する前に、テキストを選択して一致させる方法を知る必要があります。
テキストの選択
例にはテキスト ファイルが必要です。サミュエル・テイラー・コールリッジの叙事詩「The Rime of the Ancient Mariner」から抜粋した詩を含むものを使用します。
以下を入力して、
less
で確認してみます。
coleridge.txt を減らす
ファイルからいくつかの行を選択するには、選択する範囲の開始行と終了行を指定します。単一の数字でその 1 行を選択します。
1 行目から 4 行目を抽出するには、次のコマンドを入力します。
sed -n '1,4p' coleridge.txt
1
と
4
の間のカンマに注意してください。
p
「一致した行を印刷」を意味します。デフォルトでは、
sed
すべての行を出力します。ファイル内のすべてのテキストと一致する行が 2 回出力されることがわかります。これを防ぐために、
-n
(静か) オプションを使用して、一致しないテキストを抑制します。
以下に示すように、別の詩を選択できるように行番号を変更します。
sed -n '6,9p' coleridge.txt
-e
(式) オプションを使用すると、複数の選択を行うことができます。 2 つの式を使用すると、次のように 2 つの詩を選択できます。
sed -n -e '1,4p' -e '31,34p' coleridge.txt
2 番目の式の最初の数値を減らすと、2 つの節の間に空白を挿入できます。次のように入力します。
sed -n -e '1,4p' -e '30,34p' coleridge.txt
また、開始行を選択して、ファイルをステップ実行して 5 行ごとに 1 行ずつ印刷するか、任意の数の行をスキップするように
sed
に指示することもできます。このコマンドは、上で範囲を選択するために使用したものと似ています。ただし、今回は、カンマの代わりにチルダ (
~
) を使用して数値を区切ります。
最初の数字は開始ラインを示します。 2 番目の数値は、開始行の後のどの行を表示するかを
sed
指示します。数値 2 は 2 行ごと、3 は 3 行ごとなどを意味します。
次のように入力します。
sed -n '1~2p' coleridge.txt
探しているテキストがファイル内のどこにあるのか常にわかるとは限らないため、行番号は必ずしも役に立ちません。ただし、
sed
を使用して、一致するテキスト パターンを含む行を選択することもできます。たとえば、「And」で始まる行をすべて抽出してみましょう。
キャレット (
^
) は行の先頭を表します。検索語をスラッシュ (
/
) で囲みます。また、「And」の後にスペースを含めるので、「Android」などの単語が結果に含まれないようにします。
sed
スクリプトを読むのは、最初は少し難しいかもしれません。
/p
上で使用したコマンドと同様に、「印刷」を意味します。ただし、次のコマンドでは、その前にスラッシュが付いています。
sed -n '/^And /p' coleridge.txt
「And」で始まる 3 行がファイルから抽出され、表示されます。

代替を行う
最初の例では、次の
sed
置換の基本的な形式を示しました。
エコーハウツーゴンク | sed 's/gonk/geek/'
s
、これが置換であることを
sed
伝えます。最初の文字列は検索パターンで、2 番目の文字列は一致したテキストを置換するテキストです。もちろん、Linux のすべてと同様に、悪魔は細部に宿ります。
次のように入力して、出現するすべての「日」を「週」に変更し、船員とアホウドリが絆を深められる時間をさらに増やします。
sed -n 's/日/週/p' coleridge.txt
最初の行では、2 番目に出現する「day」のみが変更されます。これは、行ごとの最初の一致後に
sed
停止するためです。グローバル検索を実行して各行のすべての一致が処理されるようにするには、以下に示すように式の最後に「g」を追加する必要があります。
sed -n 's/日/週/GP' coleridge.txt
これは、最初の行の 4 つのうち 3 つと一致します。最初の単語は「Day」であり、
sed
大文字と小文字を区別するため、そのインスタンスは「day」と同じであるとは見なされません。
大文字と小文字を区別しないことを示すために、式の最後にコマンドに
i
を追加して、次のように入力します。
sed -n 's/日/週/gip' coleridge.txt
これは機能しますが、常にすべての大文字と小文字を区別しないようにしたい場合もあります。このような場合は、正規表現グループを使用して、パターン固有の大文字と小文字を区別しない機能を追加できます。
たとえば、文字を角括弧 (
[]
) で囲むと、その文字は「この文字リストの任意の文字」として解釈されます。
次のように入力し、グループに「D」と「d」を含めて、「Day」と「day」の両方に一致するようにします。
sed -n 's/[Dd]ay/week/gp' coleridge.txt
置換をファイルのセクションに制限することもできます。ファイルの最初の詩に奇妙なスペースが含まれているとします。次の使い慣れたコマンドを使用して、最初の詩を表示できます。
sed -n '1,4p' coleridge.txt
2 つのスペースを検索し、1 つのスペースに置き換えます。これをグローバルに実行して、アクションが行全体で繰り返されるようにします。明確にするために、検索パターンはスペース、スペース アスタリスク (
*
) であり、置換文字列は 1 つのスペースです。
1,4
置換をファイルの最初の 4 行に制限します。
これらすべてを次のコマンドにまとめます。
sed -n '1,4 s/ */ /gp' coleridge.txt
これはうまくいきます!ここで重要なのは検索パターンです。アスタリスク (
*
) は、0 個以上の先行文字 (スペース) を表します。したがって、検索パターンは 1 スペース以上の文字列を探します。
一連の複数のスペースを 1 つのスペースに置き換えると、ファイルは各単語の間に 1 つのスペースが入った通常のスペースに戻ります。これにより、場合によっては 1 つのスペースが 1 つのスペースに置き換えられますが、これが悪影響を与えることはありません。それでも望ましい結果が得られます。
次のように入力して検索パターンを 1 つのスペースに減らすと、2 つのスペースを含める必要がある理由がすぐにわかります。
sed -n '1,4 s/ */ /gp' coleridge.txt
アスタリスクは先行する文字の 0 個以上と一致するため、スペースではない各文字を「ゼロ スペース」とみなして置換を適用します。
ただし、検索パターンに 2 つのスペースを含める場合、
sed
置換を適用する前に少なくとも 1 つのスペース文字を見つける必要があります。これにより、スペース以外の文字はそのまま残ります。
前に使用した
-e
(式) を使用して次のように入力します。これにより、2 つ以上の置換を同時に行うことができます。
sed -n -e 's/motion/flutter/gip' -e 's/ocean/gutter/gip' coleridge.txt
次のように、セミコロン (
;
) を使用して 2 つの式を区切っても、同じ結果を得ることができます。
sed -n 's/motion/flutter/gip;s/ocean/gutter/gip' coleridge.txt
次のコマンドで「day」と「week」を交換すると、「well a-day」という式の「day」のインスタンスも同様に交換されました。
sed -n 's/[Dd]ay/week/gp' coleridge.txt
これを防ぐには、別のパターンに一致する行でのみ置換を試みることができます。先頭に検索パターンが含まれるようにコマンドを変更すると、そのパターンに一致する行での操作のみが考慮されます。
次のように入力して、一致パターンを単語「after」にします。
sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt
それにより、私たちが望む応答が得られます。

より複雑な置換
Coleridge に休憩を与えて、
sed
を使用して
etc/passwd
ファイルから名前を抽出しましょう。
これを行うためのより短い方法もあります (詳細は後ほど) が、ここでは別の概念を示すために長い方法を使用します。検索パターン (部分式と呼ばれる) で一致した各項目には、番号を付けることができます (最大 9 項目まで)。これらの数値を
sed
コマンドで使用して、特定の部分式を参照できます。
これを機能させるには、部分式を括弧 [
()
] で囲む必要があります。また、括弧が通常の文字として扱われないように、括弧の前に円記号 (
\
) を付ける必要があります。
これを行うには、次のように入力します。
sed 's/\([^:]*\).*/\1/' /etc/passwd
これを詳しく見てみましょう:
-
sed 's/:sedコマンドと置換式の始まり。 -
\(: 部分式を囲む左括弧 [(] の前にバックスラッシュ (\) が続きます。 -
[^:]*: 検索語の最初の部分式には、角かっこ内のグループが含まれます。キャレット (^) は、グループ内で使用される場合は「not」を意味します。グループとは、コロン (:以外の文字が一致として受け入れられることを意味します。 -
\): 前にバックスラッシュ (\) を付けた右括弧 [)]。 -
.*: この 2 番目の検索部分式は、「任意の文字と任意の数」を意味します。 -
/\1: 式の置換部分には、バックスラッシュ (\) が後に続く1含まれます。これは、最初の部分式に一致するテキストを表します。 -
/': 終わりのスラッシュ (/) と一重引用符 (') はsedコマンドを終了します。
これが意味するのは、コロン (
:
を含まない文字列を検索することです。これが、一致するテキストの最初のインスタンスになります。次に、その行にある他のものを検索します。これが、一致するテキストの 2 番目のインスタンスになります。行全体を最初の部分式に一致したテキストに置き換えます。
/etc/passwd
ファイルの各行は、コロンで終わるユーザー名で始まります。最初のコロンまでのすべてを照合し、その値を行全体に置き換えます。そこで、ユーザー名を分離しました。
次に、2 番目の部分式を括弧 [
()
] で囲み、番号でも参照できるようにします。また、
\1
\2
に置き換えます。このコマンドは、行全体を最初のコロン (
:
から行末までのすべてに置き換えます。
次のように入力します。
sed の/\([^:]*\)\(.*\)/\2/' /etc/passwd
これらの小さな変更によりコマンドの意味が逆転し、ユーザー名以外のすべてが取得されます。
では、これを素早く簡単に行う方法を見てみましょう。
検索語は最初のコロン (
:
から行末までです。置換式が空 (
//
) であるため、一致したテキストは何も置き換えられません。
そこで、最初のコロン (
:
から行末までをすべて切り取り、ユーザー名だけを残して次のように入力します。
sed の/:.*//" /etc/passwd
同じコマンド内で最初と 2 番目の一致を参照する例を見てみましょう。
姓と名をカンマ (
,
) で区切ったファイルがあります。 「姓、名」としてリストしたいと思います。以下に示すように、
cat
使用して、ファイルの内容を確認できます。
猫オタク.txt
多くの
sed
コマンドと同様に、次のコマンドも最初は侵入できないように見えるかもしれません。
sed 's/^\(.*\),\(.*\)$/\2,\1 /g' geeks.txt
これは、これまでに使用した他のコマンドと同様の置換コマンドであり、検索パターンは非常に簡単です。以下に詳しく説明します。
-
sed 's/: 通常の置換コマンド。 -
^: キャレットはグループ ([]) 内にないため、「行の先頭」を意味します。 -
\(.*\),: 最初の部分式は任意の数の任意の文字です。これは括弧 [()] で囲まれており、それぞれの前にバックスラッシュ (\) が付いているため、番号で参照できます。これまでの検索パターン全体は、行の先頭から最初のカンマ (,) まで、任意の数の任意の文字を検索することになります。 -
\(.*\): 次の部分式は、(やはり) 任意の数の任意の文字です。また、括弧 [()] で囲まれており、両方の前にバックスラッシュ (\) が付いているため、一致するテキストを番号で参照できます。 -
$/: ドル記号 ($) は行の終わりを表し、行の終わりまで検索を続けることができます。これは単にドル記号を導入するために使用しました。このシナリオではアスタリスク (*) が行末に来るため、ここでは実際には必要ありません。スラッシュ (/) は検索パターン セクションを完成させます。 -
\2,\1 /g': 2 つの部分式を括弧で囲んだため、両方の部分式を番号で参照できます。順序を逆にしたいので、second-match,first-matchと入力します。数字の前にはバックスラッシュ (\) を付ける必要があります。 -
/g: これにより、コマンドが各行でグローバルに動作できるようになります。 -
geeks.txt: 現在作業中のファイル。
Cut コマンド (
c
) を使用して、検索パターンに一致する行全体を置き換えることもできます。次のように入力して、「neck」という単語を含む行を検索し、新しいテキスト文字列に置き換えます。
sed '/neck/c 手首のあたりが張られていました' coleridge.txt
新しい行が抽出の最後に表示されます。

線とテキストの挿入
ファイルに新しい行やテキストを挿入することもできます。一致する行の後に新しい行を挿入するには、追加コマンド (
a
) を使用します。
ここで扱うファイルは次のとおりです。
猫オタク.txt
もう少しわかりやすくするために、行に番号を付けました。
次のように入力して、「He」という単語を含む行を検索し、その下に新しい行を挿入します。
sed '/He/a --> 挿入されました!'オタク.txt
次のように入力し、一致するテキストを含む行の上に新しい行を挿入する挿入コマンド (
i
) を含めます。
sed '/He/i --> 挿入されました!'オタク.txt
元の一致したテキストを表すアンパサンド (
&
) を使用して、一致する行に新しいテキストを追加できます。
\1
、
\2
などは、一致する部分式を表します。
行の先頭にテキストを追加するには、その行のすべてに一致する置換コマンドを使用し、新しいテキストと元の行を結合する置換句を組み合わせます。
これらすべてを行うには、次のように入力します。
sed 's/.*/--> &/' geeks.txt を挿入しました
G
コマンドを含めて次のように入力します。これにより、各行の間に空白行が追加されます。
sed 'G' geeks.txt
2 つ以上の空白行を追加する場合は、
G;G
、
G;G;G
などを使用できます。

行の削除
削除コマンド (
d
) は、検索パターンに一致する行、または行番号または範囲で指定された行を削除します。
たとえば、3 行目を削除するには、次のように入力します。
sed '3d' geeks.txt
4 行目から 5 行目の範囲を削除するには、次のように入力します。
sed '4,5d' geeks.txt
範囲外の行を削除するには、以下に示すように感嘆符 (
!
) を使用します。
sed '6,7!d' geeks.txt
変更を保存する
これまでのところ、すべての結果はターミナル ウィンドウに出力されていますが、まだどこにも保存していません。これらを永続的にするには、変更を元のファイルに書き込むか、新しいファイルにリダイレクトします。
元のファイルを上書きする場合は、ある程度の注意が必要です。
sed
コマンドが間違っていると、元のファイルに元に戻すのが困難な変更が加えられる可能性があります。
安心のため、
sed
コマンドを実行する前に元のファイルのバックアップを作成できます。
インプレース オプション (
-i
) を使用すると、変更を元のファイルに書き込むように
sed
に指示できますが、ファイル拡張子を追加すると、
sed
元のファイルを新しいファイルにバックアップします。元のファイルと同じ名前になりますが、新しいファイル拡張子が付きます。
デモとして、「He」という単語を含む行を検索して削除します。また、BAK 拡張子を使用して、元のファイルを新しいファイルにバックアップします。
これらすべてを行うには、次のように入力します。
sed -i'.bak' '/^.*He.*$/d' geeks.txt
次のように入力して、バックアップ ファイルが変更されていないことを確認します。
猫オタク.txt.bak
次のように入力して出力を新しいファイルにリダイレクトし、同様の結果を達成することもできます。
sed -i'.bak' '/^.*He.*$/d' geeks.txt > new_geeks.txt
以下に示すように、
cat
を使用して変更が新しいファイルに書き込まれたことを確認します。
猫 new_geeks.txt
すべてを送信した
お気づきかと思いますが、この
sed
の入門書でもかなり長いです。このコマンドには多くの機能があり、
それを使用してできることはさらにたくさん
あります。
ただし、これらの基本概念が、さらに学習を続ける際に構築できる強固な基盤となったことを願っています。




