
重要なポイント
- Linux の Cut コマンドを使用すると、ファイルまたはデータ ストリームからテキストの一部を抽出できます。
- Cut はバイト、文字、区切りフィールドで機能し、条件に基づいてテキストの特定の部分を選択できます。
- Cut を greg などの他のユーティリティと組み合わせて、より複雑な操作を実行できます。
Linux の
cut
コマンドを使用すると、ファイルまたはデータ ストリームからテキストの一部を抽出できます。これは、
CSV ファイル
などの区切り文字で区切られたデータを操作する場合に特に便利です。知っておくべきことは次のとおりです。
カットコマンド
cut
コマンドは
Unix
界のベテランであり、AT&T System III UNIX の一部として 1982 年にデビューしました。その目的は、設定した基準に従ってファイルまたはストリームからテキストのセクションを切り取ることです。その構文は目的と同じくらい単純ですが、この結合の単純さが非常に便利です。
伝統的な UNIX の方法で、
cut
grep
などの
他のユーティリティと組み合わせることで、困難な問題に対する洗練された強力なソリューションを作成できます。
cut
にはさまざまなバージョンがありますが、ここでは標準の GNU/Linux バージョンについて説明します。他のバージョン、特に
BSD
バリアントにある
cut
には、ここで説明するすべてのオプションが含まれていないことに注意してください。
次のコマンドを実行すると、コンピュータにどのバージョンがインストールされているかを確認できます。
カット --バージョン
出力に「GNU coreutils」と表示されている場合は、この記事で説明するバージョンを使用しています。
cut
のすべてのバージョンにこの機能の一部が備わっていますが、Linux バージョンには拡張機能が追加されています。

はじめの一歩 カット付き
情報を
cut
にパイプする場合でも、
cut
使用して
ファイルを読み取る
場合でも、使用するコマンドは同じです。
cut
を使用して入力ストリームに対して実行できることはすべて、ファイルのテキスト行に対して実行でき、その逆も同様です。
cut
にバイト、文字、または区切り文字で区切られたフィールドを処理するように指示できます。
単一バイトを選択するには、
-b
(バイト) オプションを使用して、どのバイトが必要かを
cut
指示します。この場合、それはバイト 5 です。
echo
からパイプ「|」を使用して、文字列「how-to geek」を
cut
コマンドに送信しています。
エコー「ハウツーオタク」 |カット -b 5
この文字列の 5 番目のバイトは「t」であるため、
cut
端末ウィンドウに「t」を出力して応答します。
範囲を指定するにはハイフンを使用します。バイト 5 から 11 までを抽出するには、次のコマンドを発行します。
エコー「ハウツーオタク」 |カット -b 5-11
カンマで区切ることにより、複数の単一バイトまたは範囲を指定できます。バイト 5 とバイト 11 を抽出するには、次のコマンドを使用します。
エコー「ハウツーオタク」 |カット -b 5,11
各単語の最初の文字を取得するには、次のコマンドを使用できます。
エコー「ハウツーオタク」 |カット -b 1,5,8
最初の数字を付けずにハイフンを使用すると、
cut
位置 1 から数字までのすべてを返します。 2 番目の数値を指定せずにハイフンを使用すると、
cut
最初の数値からストリームまたは行の終わりまでのすべてを返します。
エコー「ハウツーオタク」 |カット -b -6
エコー「ハウツーオタク」 |カット -b 8-

文字付きカットの使用
文字での
cut
使用は、バイトでの使用とほぼ同じです。どちらの場合も、複雑な文字には特別な注意が必要です。
-c
(文字) オプションを使用すると、
cut
バイトではなく文字で動作するように指示されます。
エコー「ハウツーオタク」 |カット -c 1,5,8
エコー「ハウツーオタク」 |カット -c 8-11
これらは期待どおりに機能します。しかし、この例を見てください。これは 6 文字の単語なので、
cut
1 から 6 までの文字を返すように要求すると、単語全体が返されるはずです。しかし、そうではありません。一文字短いですね。単語全体を見るには、1 から 7 までの文字を尋ねる必要があります。
エコー「ピニャータ」 |カット -c 1-6
エコー「ピニャータ」 |カット -c 1-7
問題は、文字「ñ」が実際には 2 バイトで構成されていることです。これは非常に簡単にわかります。次のテキスト行を含む短い テキスト ファイル があります。
猫のユニコード.txt
hexdump
ユーティリティを使用して
そのファイルを調べ
ます。
-C
(正規) オプションを使用すると、右側に
相当する ASCII
数字を含む 16 進数の表が表示されます。 ASCII テーブルでは、「ñ」は表示されず、代わりに 2 つの印刷不可能な文字を表すドットがあります。これらは、
16 進数の
テーブルで強調表示されているバイトです。
hexdump -C unicode.txt
これら 2 バイトは、表示プログラム (この場合は Bash シェル ) によって「ñ」を識別するために使用されます。多くの Unicode 文字は、 1 つの文字を表すために 3 バイト以上を使用します。
文字 3 または文字 4 を要求すると、非印刷文字のシンボルが表示されます。バイト 3 と 4 を要求すると、シェルはそれらを「ñ」と解釈します。
エコー「ピニャータ」 |カット -c 3
エコー「ピニャータ」 |カット -c 4
エコー「ピニャータ」 |カット -c 3-4

区切りデータでカットを使用する
cut
に指定した区切り文字を使用してテキスト行を分割するように依頼できます。デフォルトでは、cut はタブ文字を使用しますが、必要なものを使用するように指示するのは簡単です。 「/etc/passwd」ファイル内のフィールドはコロン「:」で区切られているため、これを区切り文字として使用し、テキストを抽出します。
区切り文字間のテキスト部分はフィールドと呼ばれ、バイトや文字と同じように参照されますが、その前に
-f
(フィールド) オプションが付きます。 「f」と数字の間にスペースを入れても入れなくても構いません。
最初のコマンドは、
-d
(区切り文字) オプションを使用して、cut に区切り文字として「:」を使用するように指示します。 「/etc/passwd」ファイルの各行から最初のフィールドが抽出されます。これは長いリストになるため、
-n
(数字) オプションを付けて
head
使用して、最初の 5 つの応答のみを表示します。 2 番目のコマンドは同じことを行いますが、
tail
を使用して最後の 5 つの応答を表示します。
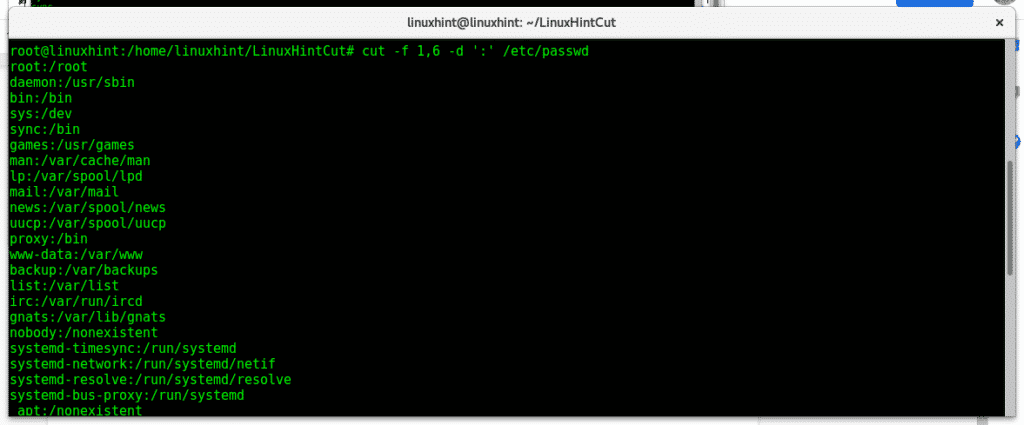
カット -d':' -f1 /etc/passwd |頭 -n 5
カット -d':' -f2 /etc/passwd |尾-n 5
選択したフィールドを抽出するには、フィールドをカンマ区切りのリストとしてリストします。このコマンドは、フィールド 1 ~ 3、5、および 6 を抽出します。
カット -d':' -f1-3,5,6 /etc/passwd |尾-n 5
コマンドに
grep
含めることで、「/bin/bash」を含む行を検索できます。これは、Bash をデフォルトのシェルとして持つエントリのみをリストできることを意味します。通常、これは「通常の」ユーザー アカウントになります。 7 番目のフィールドはデフォルトのシェル フィールドであり、それが何であるかをすでに知っており、それを検索しているため、1 から 6 までのフィールドを要求します。
grep "/bin/bash" /etc/passwd |カット -d':' -f1-6
1 つのフィールドを除くすべてのフィールドを含める別の方法は、
--complement
オプションを使用することです。これにより、フィールドの選択が反転され、要求されていないものがすべて表示されます。最後のコマンドを繰り返しますが、フィールド 7 のみを要求します。次に、
--complement
オプションを使用してそのコマンドを再度実行します。
grep "/bin/bash" /etc/passwd |カット -d':' -f7
grep "/bin/bash" /etc/passwd | Cut -d':' -f7 --complement
最初のコマンドはエントリのリストを検索しますが、フィールド 7 ではそれらを区別するものが何もないため、エントリが誰を参照しているのかわかりません。 2 番目のコマンドでは、
--complement
オプションを追加することで、フィールド 7 以外のすべてを取得します。

配管カット カットイン
「/etc/passwd」ファイルをそのままにして、フィールド 5 を抽出しましょう。これは 、ユーザー アカウントを所有する ユーザーの実際の名前です。
grep "/bin/bash" /etc/passwd |カット -d':' -f5
5 番目のフィールドには、カンマで区切られたサブフィールドがあります。これらはめったに設定されないため、カンマ行として表示されます。
前のコマンドの出力を別の
cut
呼び出しにパイプすることで、コンマを削除できます。
cut
の 2 番目のインスタンスでは、区切り文字としてコンマ「,」が使用されます。
-s
(区切り文字のみ) オプションは、区切り文字がまったく含まれていない結果を抑制するように
cut
指示します。
grep "/bin/bash" /etc/passwd |カット -d':' -s -f5 |カット -d',' -s -f1
ルート エントリの 5 番目のフィールドにカンマ サブフィールドがないため、このエントリは抑制され、目的の結果、つまりこのコンピュータ上に構成されている「実際の」ユーザーの名前のリストが得られます。
出力デリミタ
いくつかのカンマ区切り値を含む小さなファイルがあります。このダミー データのフィールドは次のとおりです。
- ID : データベースのID番号
- First : 被験者の名。
- Last : 被験者の姓。
- email : メールアドレス。
- IP アドレス : ユーザーの IP アドレス 。
- ブランド : 彼らが運転する自動車のブランド。
- モデル : 彼らが運転する自動車のモデル。
- Year : 自動車が製造された年。
猫小.csv
Cut にカンマを区切り文字として使用するように指示すると、前と同じようにフィールドを抽出できます。ファイルからデータを抽出する必要があるが、結果にフィールド区切り文字を含めたくない場合があります。
--output-delimiter
を使用すると、実際の区切り文字の代わりにどの文字 (実際には文字シーケンス) を使用するかを指定できます。
カット -d ',' -f 2,3 small.csv
カット -d ',' -f 2,3 small.csv --output-delimiter=' '
2 番目のコマンドは
cut
にカンマをスペースに置き換えるよう指示します。
これをさらに進めて、この機能を使用して出力を垂直リストに変換できます。このコマンドは、出力区切り文字として改行文字を使用します。 「$」は改行文字を処理するために含める必要があり、2 つの文字のリテラルシーケンスとして解釈されないことに注意してください。
grep
を使用して Morgana Renwick のエントリをフィルターで除外し、フィールド 2 からレコードの最後までのすべてのフィールドを印刷し、出力区切り文字として改行文字を使用するように
cut
依頼します。
grep 'レンウィック' small.csv |カット -d ',' -f2- --output-delimiter=$''

オールディーだけどゴールディー
これを書いている時点で、little Cut コマンドは 40 歳の誕生日を迎えようとしていますが、私たちは今でもそれを使用し、それについて書いています。今でも文章を切り取るのは40年前と同じだと思います。つまり、適切なツールが手元にあれば、はるかに簡単になります。




