
Linux または macOS コンピューターは仮想メモリを使用しています。システムの物理メモリ、CPU、ハードディスク リソースの使用にどのような影響を与えているかを確認します。
仮想メモリとは何ですか?
コンピュータには 、ランダム アクセス メモリ (RAM) と呼ばれる有限量の物理メモリが搭載されています。この RAM はカーネルによって管理され、オペレーティング システムと実行中のアプリケーションの間で共有される必要があります。これらの複合的な需要により、コンピューターに物理的にインストールされているメモリよりも多くのメモリが必要な場合、カーネルは何ができるでしょうか?
Linux や macOS などの Unix 系 オペレーティング システムは、ハード ディスク上の領域を使用してメモリ需要を管理できます。 「スワップスペース」と呼ばれるハードドライブスペースの予約領域は、RAMの拡張であるかのように使用できます。これが仮想メモリです。
Linux カーネルは、メモリ ブロックの内容をスワップ領域に書き込み、RAM のその領域を別のプロセスで使用できるように解放できます。スワップアウトされたメモリ (「ページアウト」とも呼ばれる) は、必要に応じてスワップ スペースから取得し、RAM に復元できます。
もちろん、ページアウトされたメモリのアクセス速度は、RAM に保持されているメモリのアクセス速度よりも遅くなります。トレードオフはそれだけではありません。仮想メモリは、Linux がメモリ需要を管理する方法を提供しますが、仮想メモリを使用すると、コンピュータの他の部分の負担が増加します。
ハードドライブはより多くの読み取りと書き込みを実行する必要があります。カーネル、つまり CPU は、メモリをスワップアウト、スワップインし、さまざまなプロセスのメモリニーズを満たすためにすべてのプレートを回転させ続けるため、より多くの作業を実行する必要があります。
Linux では、
仮想メモリの統計情報
を報告する
vmstat
コマンドの形式でこのアクティビティすべてを監視する方法が提供されています。

vmstat コマンド
パラメーターを指定せずに
vmstat
コマンドとして入力すると、一連の値が表示されます。これらの値は、コンピュータが最後に再起動されてからの各統計の平均です。これらの数字は「現時点」の値のスナップショットではありません。
vmstat
値の短い表が表示されます。
Procs、Memory、Swap、IO、System、CPU という見出しの列があります。最後の列 (一番右側の列) には、CPU に関連するデータが含まれています。
各列のデータ項目のリストは次のとおりです。
プロシージャ
- r: 実行可能なプロセス数。これらは、起動されて実行中か、次のタイムスライスされた CPU サイクルのバーストを待っているプロセスです。
- b: 無中断スリープ中のプロセスの数。プロセスはスリープ状態ではなく、ブロッキング システム コールを実行しており、現在のアクションが完了するまで中断できません。通常、このプロセスは、リソースが解放されるのを待つデバイス ドライバーです。そのプロセスのキューに入れられた割り込みは、プロセスが通常のアクティビティを再開したときに処理されます。
メモリ
- swpd: 使用されている仮想メモリの量。言い換えれば、どれだけのメモリがスワップアウトされたかということです。
- free: アイドル状態の (現在未使用の) メモリの量。
- buff: バッファとして使用されるメモリの量。
- キャッシュ: キャッシュとして使用されるメモリの量。
スワップ
- si: スワップスペースからスワップインされた仮想メモリの量。
- so: スワップ領域にスワップアウトされた仮想メモリの量。
IO
- bi: ブロックデバイスから受信したブロック。仮想メモリを RAM に戻すために使用されるデータ ブロックの数。
- bo: ブロックデバイスに送信されるブロック。仮想メモリを RAM からスワップ領域にスワップするために使用されるデータ ブロックの数。
システム
- in: クロックを含む、1 秒あたりの割り込み数。
- cs: 1 秒あたりのコンテキスト スイッチの数。コンテキストスイッチは、カーネルがシステムモード処理からユーザーモード処理に切り替わるときです。
CPU
これらの値はすべて、合計 CPU 時間のパーセンテージです。
- us: カーネル以外のコードの実行に費やした時間。つまり、ユーザー時間の処理とナイスタイムの処理にどれだけの時間が費やされるかということです。
- sy: カーネル コードの実行に費やした時間。
- id: アイドル状態で過ごした時間。
- wa: 入力または出力の待機に費やした時間。
- st: 仮想マシンから盗まれた時間。これは、仮想マシンが戻ってこの仮想マシンを処理できるようになるまで、ハイパーバイザーが他の仮想マシンへのサービスを終了するまで待機する必要がある時間です。

時間間隔の使用
delay
値を使用して、
vmstat
にこれらの数値を定期的に更新させることができます。
delay
値は秒単位で指定されます。統計を 5 秒ごとに更新するには、次のコマンドを使用します。
vmstat 5
vmstat
5 秒ごとにテーブルにデータ行を追加します。これを停止するには、Ctrl+C を押す必要があります。

カウント値の使用
delay
値が低すぎると、システムにさらなる負担がかかります。問題を診断するために迅速な更新が必要な場合は、
delay
値だけでなく
count
値も使用することをお勧めします。
count
値は、vmstat が終了してコマンド プロンプトに戻るまでに実行する更新の回数を
vmstat
指示します。
count
値を指定しない場合、
vmstat
Ctrl+C で停止されるまで実行されます。
vmstat
に 5 秒ごとに更新を提供させるには (ただし 4 回の更新のみ)、次のコマンドを使用します。
vmstat 5 4
4 回更新すると、
vmstat
自動的に停止します。
単位を変更する
-S
(単位文字) オプションを使用すると、メモリとスワップの統計をキロバイトまたはメガバイトで表示するように選択できます。この後には、
k
、
K
、
m
、または
M
のいずれかが続く必要があります。これらは次のことを表します。
- k:1000バイト
- K:1024バイト
- m:1000000バイト
- M: 1048576バイト
統計を 10 秒ごとに更新し、メモリおよびスワップの統計をメガバイト単位で表示するには、次のコマンドを使用します。
vmstat 10 -SM
メモリとスワップの統計がメガバイト単位で表示されるようになりました。
-S
オプションは IO ブロック統計に影響を与えないことに注意してください。これらは常にブロックで表示されます。
アクティブなメモリと非アクティブなメモリ
-a
(アクティブ) オプションを使用すると、buff およびキャッシュ メモリ列が「inact」列と「active」列に置き換えられます。彼らが示唆しているように、これらは非アクティブなメモリとアクティブなメモリの量を示します。
buff 列とキャッシュ列の代わりにこれら 2 つの列を表示するには、次のように
-a
オプションを含めます。
vmstat 5 -a -SM
無効な列とアクティブな列は、-S (単位文字) オプションの影響を受けます。

フォーク
-f
スイッチは、コンピュータの起動以降に発生したフォークの数を表示します。
言い換えれば、これは、システムの起動以降に起動された (そして、大部分は再び閉じられた) タスクの数を示します。コマンドラインからプロセスを起動するたびに、この数値は増加します。タスクまたはプロセスが新しいタスクを生成または複製するたびに、この数値は増加します。
vmstat -f
フォークの表示が更新されません。
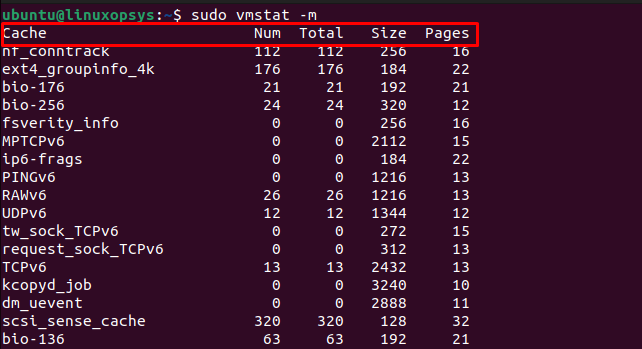
スラブ情報の表示
カーネルには、オペレーティング システムとすべてのアプリケーションのメモリ管理だけでなく、独自のメモリ管理も考慮する必要があります。
ご想像のとおり、カーネルは、処理する必要があるさまざまな種類のデータ オブジェクトに対して、メモリの割り当てと割り当て解除を繰り返し行っています。これを可能な限り効率的に行うために、スラブと呼ばれるシステムが使用されます。これはキャッシュの一種です。
特定のタイプのカーネル データ オブジェクトに割り当てられ、使用され、不要になったメモリは、メモリの割り当てを解除して再割り当てすることなく、同じタイプの別のデータ オブジェクトに再利用できます。スラブは、カーネル自身のニーズに合わせて事前に割り当てられた、特注の RAM セグメントであると考えてください。
スラブの統計を表示するには、
-m
(スラブ) オプションを使用します。
sudo
を使用する必要があり、パスワードの入力を求められます。出力は非常に長くなる可能性があるため、
less
を通じてパイプしています。
sudo vmstat -m |少ない
出力には 5 つの列があります。これらは:
- キャッシュ: キャッシュの名前。
- num: このキャッシュ内で現在アクティブなオブジェクトの数。
- total: このキャッシュ内で使用可能なオブジェクトの合計数。
- size: キャッシュ内の各オブジェクトのサイズ。
- ページ: 現在このキャッシュに関連付けられている (少なくとも) 1 つのオブジェクトを持つメモリ ページの総数。
残りを
less
には
q
押してください。
イベントカウンターとメモリ統計の表示
イベント カウンターとメモリ統計のページを表示するには、
-s
(stats) オプションを使用します。小文字の「s」であることに注意してください。
vmstat -s
報告される統計情報は、デフォルトの
vmstat
出力を構成する情報とほぼ同じですが、一部はより詳細に分割されています。
たとえば、デフォルトの出力では、nice ユーザー CPU 時間と非nice ユーザー CPU 時間の両方が「us」列に結合されます。 -s (統計) 表示では、これらの統計が個別にリストされます。
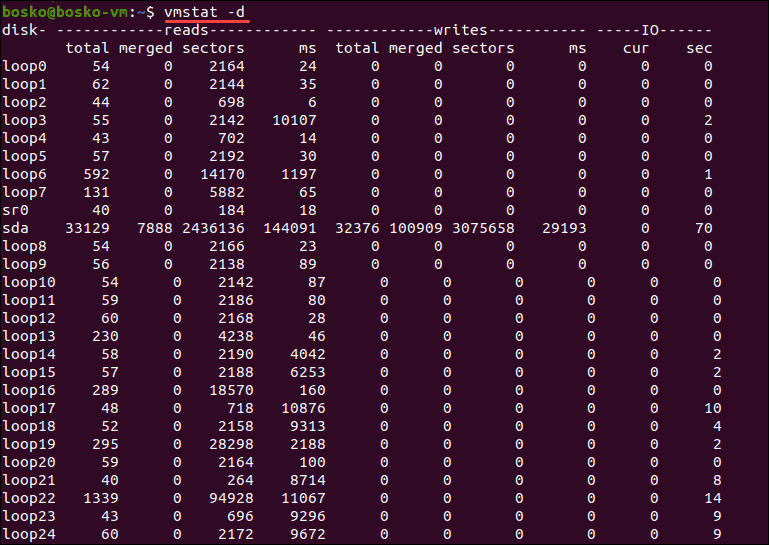
ディスク統計の表示
-d
(ディスク) オプションを使用すると、ディスク統計の同様のリストを取得できます。
vmstat -d |少ない
各ディスクについて、読み取り、書き込み、および IO の 3 つの列が表示されます。
IO は右端の列です。 IO の sec 列は秒単位で測定されますが、読み取り列と書き込み列の時間ベースの統計はミリ秒単位で測定されることに注意してください。
列の意味は次のとおりです。
読み取り
- total: ディスク読み取りの合計数。
- マージ済み: グループ化された読み取りの合計数。
- セクター: 読み込まれたセクターの総数。
- ms: ディスクからのデータの読み取りに費やされた合計時間 (ミリ秒単位)。
書きます
- total: ディスク書き込みの合計数。
- マージ済み: グループ化された書き込みの合計数。
- セクター: 書き込まれたセクターの総数。
- ms = ディスクへのデータの書き込みに要した合計時間 (ミリ秒単位)。
IO
- cur: 現在のディスクの読み取りまたは書き込みの数。
- sec: 進行中の読み取りまたは書き込みに費やされた時間 (秒単位)。
ディスク統計の概要の表示
ディスク アクティビティの概要統計を簡単に表示するには、
-D
(disk-sum) オプションを使用します。大文字の「D」に注意してください。
vmstat -D
ディスクの数が異常に多く見える場合があります。この記事の調査に使用したコンピューターは Ubuntu を実行しています。 Ubuntu では、Snap からアプリケーションをインストールするたびに、/dev/loop デバイスに接続される
squashfs
疑似ファイルシステムが作成されます。
厄介なことに、これらのデバイス エントリは、多くの Linux コマンドやユーティリティによってハード ドライブ デバイスとしてカウントされます。
パーティション統計の表示
特定のパーティションに関連する統計を表示するには、
-p
(パーティション) オプションを使用し、コマンド ライン パラメーターとしてパーティション識別子を指定します。
ここでは、パーティション
sda1
を見ていきます。数字の 1 は、これがデバイス
sda
上の最初のパーティションであることを示します。これは、このコンピュータのメイン ハード ドライブです。
vmstat -p sda1
返される情報には、そのパーティションに対するディスク読み取りとディスク書き込みの合計数、およびディスク読み取りとディスク書き込みアクションに含まれるセクター数が表示されます。
ボンネットの下を覗く
ボンネットを持ち上げて、その下で何が起こっているかを確認する方法を知っておくことは常に良いことです。問題を解決しようとする場合もあれば、コンピューターがどのように動作するかを知りたいために興味がない場合もあります。
vmstat
、大量の有用な情報を提供します。これで、アクセス方法とその意味がわかりました。そして、事前に警告することは事前に準備しておきます。袖をまくって診断を行う必要がある場合には、
vmstat
味方であることがわかります。
関連: 開発者と愛好家のための最高の Linux ラップトップ




