
重要なポイント
- Large Language Model (LLM) は、ChatGPT や Google Bard などの AI チャットボットを強化し、リクエストを処理して応答を提供できるようにします。
- LLM は、テキストを生成しプロンプトに応答する方法を決定するために、膨大な量のデータと一連のパラメーターの事前トレーニングに依存しています。
- AI チャットボットなどの LLM には、事実の提供、テキストの翻訳、アイデアの生成、検索エンジンの結果の強化など、さまざまな用途があります。
ChatGPT のような AI チャットボットは現在非常に人気がありますが、私たちの多くはまだその仕組みを理解していません。これらのチャットボットは LLM を利用しており、このテクノロジーには将来の大きな可能性が秘められています。では、LLM とは何ですか?また、LLM によって AI はどのようにして人間と会話できるようになるのでしょうか?
LLMとは何ですか?
「LLM」という用語は、Large Language Model の略称です。大規模な言語モデルは 、 ChatGPT や Google Bard などの AI チャットボットのフレームワークを提供し、リクエストを処理して応答を提供できるようにします。
会話型コンピューターの概念は、このテクノロジーの最初の例が実用化されるずっと前から存在していました。 1930 年代に会話型コンピューターのアイデアが生まれましたが、完全に理論的なものにとどまっていました。数十年後の 1967 年に、世界初のチャットボット ELIZA が作成されました。 MIT のジョゼフ・ワイゼンバウムによって開発された ELIZA は、「パターン マッチング」として知られる戦術を使用してユーザーと会話し、応答を引き出すための会話スクリプトのストックを使用するテキスト ベースのプログラムでした。
ニュージャージー工科大学は、現在でも対話可能な Web ベースの ELIZA バージョンを提供しています 。
ご覧のとおり、ELIZA は言語を解釈して有益な情報を提供するのが得意ではありません。しかし、1960 年代に発明されたこのチャットボットは、比較的人間らしい方法でプロンプトに応答でき、会話を継続する機能も備えていたため、画期的でした。上記で、私たちはELIZAに悲しいことを伝えました。そして、ELIZAは私たちにもっとそれを伝えて、どれくらいの間そのように感じていたのか尋ねることができました。
ELIZA は革新的な発明ではありましたが、LLM ではありませんでした。実際、今日の LLM に近いテクノロジーが実現されるまでにはさらに 47 年かかりました。
2013 年に、 word2vec として知られるアルゴリズムが LLM の最新の祖先になりました。 Word2vec は、1 つの単語を取得し、それをベクトルと呼ばれる数値の配列に変換するために使用される自然言語処理 (NLP) アルゴリズムです。一見すると基本的なことのように思えるかもしれませんが、word2vec の驚くべき点は、異なる単語をベクトル化した後にそれらの間に意味的なつながりを作成できることです。単語間の関連付けを作成できるこの機能は、現代の LLM への大きな一歩となりました。
多くの人が OpenAI とそのチャットボットである ChatGPT を LLM の父と関連付けていますが、そうではありません。 LLM の最初のブレークスルーは、2017 年に Google によって Bidirectional Encoder Representations from Transformers (BERT) によって実現されました。 BERT は、Google の検索エンジン アルゴリズムを改善することを目的として開発されました。これにより、ユーザーの検索をより適切に解釈できるようになり、結果として改善された検索結果が提供されます。
BERT のリリースに先立って、Google の研究者数名が 「 Attending Is All You Need 」 というタイトルの論文を執筆し、発表しました。この論文は変圧器の基礎を整え、この技術を世界に紹介しました。変圧器の仕組みについては後ほどもう少し詳しく説明します。
2022 年、ChatGPT、 Claude 、Google Bard などの AI チャットボットが大流行し、LLM が主流になりました。 OpenAI の ChatGPT-3.5 のリリースは、チャットボットが人間の言語を非常に効率的に処理できる非常に印象的な会話型 AI ツールを提供したため、この新しいトレンドのきっかけとなりました。それ以来、LLM は大きな話題となり、LLM ベースのツールが毎週リリースされています。
では、この素晴らしいテクノロジーの背後には何があるのでしょうか?

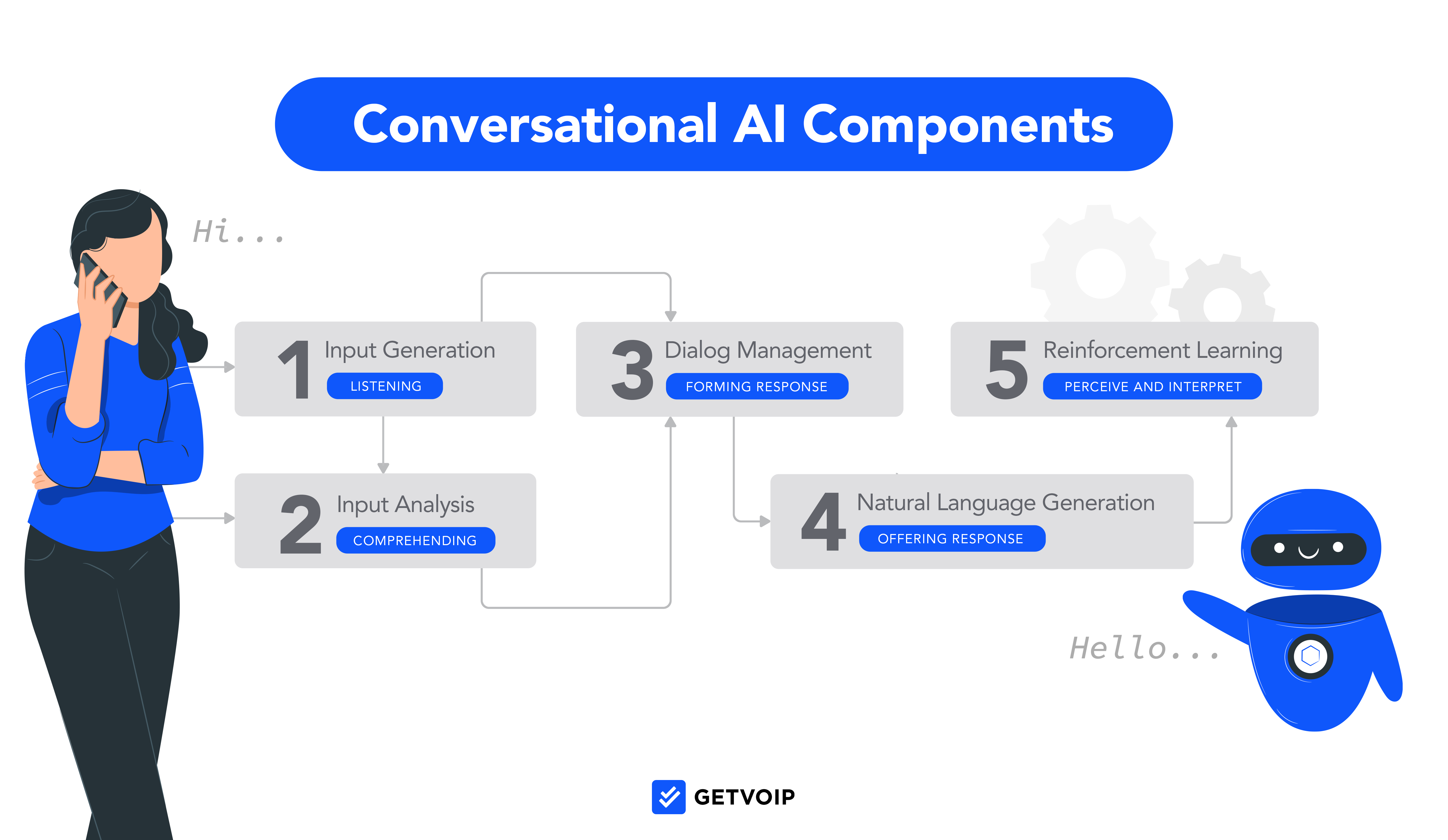
LLM はどのように機能しますか?
多くの人気のある LLM が必要とする重要な要素は、事前トレーニングです。 LLM を処理言語として機能させる前に、一連のパラメーターだけでなく、膨大な量のデータでトレーニングする必要があります。
たとえば、OpenAI の GPT-3.5 を考えてみましょう。この LLM は、書籍、記事、学術雑誌、Web ページ、オンライン投稿などを含む、あらゆる種類のテキストベースのデータでトレーニングされました。これに加えて、GPT-3.5 がどのようにテキストを生成し、プロンプトに応答するかを決定するために、「パラメーター」として知られる数十億の変数が設定されます。 GPT-3.5 のトレーニングには、「強化」と「次の単語の予測」として知られる他の 2 つの側面も含まれています。
ただし、他の種類の LLM は、マルチモーダルや微調整など、異なる準備プロセスを経ます。たとえば、OpenAI の DALL-E は、プロンプトに基づいて画像を生成するために使用され、マルチモーダルなアプローチを使用してテキストベースの応答を取得し、代わりにピクセルベースの画像を提供します(つまり、ある形式の入力メディアが別の形式に変換されます)出力メディアの形式)。
一方、Google の BERT は、微調整として知られる予備プロセスを経ます。このプロセスでは、自然言語による応答の生成には重点が置かれておらず、テキスト分類や質問応答などのより具体的なタスクに応答することに重点が置かれています (これにより、応答の質が向上します)。の検索結果)。
LLM は機能するためにニューラル ネットワークにも依存しており、最も一般的に使用されるタイプはトランスフォーマーとして知られています。以下は変圧器のプロセスを示す基本的な図ですが、変圧器がどのように機能するかをよりよく理解するためにさらに詳しく掘り下げていきます。
トランスフォーマー ニューラル ネットワークは、次にどの単語が来るか、および与えられた文内の各単語の重要性とコンテキストをシステムが予測できるようにする上で重要な役割を果たします。トランスフォーマー モデル内にはエンコーダー ステップとデコーダー ステップがあり、それぞれが複数のレイヤーで構成されます。まず、テキストベースのデータがエンコーダーに到達し、数値に変換されます。
これらの個々の数値単位はトークンとも呼ばれ、AI チャットボットについて議論するときに「トークン制限」という言葉を聞くことがあります。
これらのトークンはトランスフォーマーによって分類され、各トークンの重要性と、あるトークンが他のトークンとどのように関係するかのマップが作成されます。つまり、トランスフォーマーは、作成された数値マップを使用して、データの周囲のコンテキストと、あるトークンが別のトークンにどのように接続されているかを理解します。このプロセスは、トランスフォーマー セルフ アテンション、またはマルチヘッド アテンションとしても知られています。
セルフアテンションには、さまざまな入力トークンを相互に比較しながら、トランスフォーマーが複数の計算を同時に実行することが含まれます。これから、出力注意スコアが各トークンまたは単語に対して計算されます。単語が注目を集めるほど、出力 (または応答) を作成するときにその単語がより重要に考慮されます。
次に、数値データをテキストベースの応答にデコードします。このプロセスでは、エンコードされた入力トークンがテキストベースの出力トークンに変換され、プロンプトに対する LLM の応答が形成されます。
トランスフォーマーがなければ、文脈、ニュアンス、単語間の関係を判断できず、LLM の応答が効果的でないか、意味不明になるため、LLM は実質的に役に立たなくなります。

LLM はどこで使用されますか?
現在、Claude、LaMDA、LLaMA、Cohere、 GPT-3.5、GPT-4 などの主要な LLM がいくつか存在します。これらの LLM の多くは Google や Meta などの有名なテクノロジー大手によって開発されましたが、その他の LLM は OpenAI や Anthropic などの AI に重点を置いた企業の製品です。
LLM が動作している最もよく知られた例は、Bard、ChatGPT、Claude、Bing Chat などの AI チャットボットです。これらの気の利いたツールは、OpenAI が GPT-3.5 をリリースした後、2022 年後半に人気が高まり始めました。それ以来、LLM の適用範囲は大幅に拡大しましたが、AI チャットボットは依然として非常に人気があります。
AIチャットボットはユーザーに無数のサービスを提供できるからです。これらのツールに、事実の提供、テキストの翻訳、アイデアの生成、ジョークの発言、詩や歌の作成などを依頼できます。 AI チャットボットの多用途性により、AI チャットボットはあらゆる分野で役立ち、企業はさらに優れたエクスペリエンスを実現するために AI チャットボットの改良に継続的に取り組んでいます。
しかし、AI チャットボットだけでは終わりません。非常によく知られた LLM の中には、チャットボット環境の外で使用されるものもあります。たとえば、Google の BERT は検索エンジンの結果の品質を向上させるために使用されており、チャットボット ベースの LLM が普及する数年前に使用されていました。
LLM テクノロジーがいかに新しいかを考えると、将来的に適用される可能性のある用途も数多くあります。 LLM は、医療業界、特に研究分析、患者シナリオのシミュレーション、退院概要、医療照会などで役立つことが証明されています。ただし、LLM の最新のバージョンでは依然として事実の不正確さ、トレーニング データの制限、 AI の幻覚 に悩まされているため、医療用途にはまだ適していない可能性があります。
LLM はエキサイティングな新テクノロジーです
LLM は、2017 年に正式に発明されたばかりで、まだ初期段階にあります。しかし、LLM ベースのツールは、かつてはコンピューターでは不可能だった機能をすでに提供しており、この言語処理方法の可能性は本当に驚くべきものです。近い将来、LLM はさらに進歩し、より多くの業界がこのテクノロジーを採用するようになるかもしれません。




