
スキルを習得するには、知識を収集し、慎重に練習し、パフォーマンスを監視します。最終的には、その活動がより上手になります。機械学習は、コンピューターにまさにそれを可能にする技術です。
コンピューターは学習できるのか?
知能の定義は難しい。知性という言葉が何を意味するかは誰もが知っていますが、それを説明するのは問題があります。感情や自己認識はさておき、実用的な記述とは、新しいスキルを学び、知識を吸収し、それらを新しい状況に適用して望ましい結果を達成する能力である可能性があります。
知能の定義が難しいことを考えると、人工知能を定義するのは決して簡単ではありません。そこで、少し騙してみます。通常人間の推論と知性が必要な処理をコンピューティング デバイスが実行できる場合、それは人工知能を使用していると言えます。
たとえば、
Amazon Echo
や
Google Nest
などのスマート スピーカーは、私たちの音声による指示を聞き、その音を単語として解釈し、単語の意味を抽出して、私たちのリクエストを実行しようとします。私たちは、
音楽を再生し
たり、
、
照明を暗くしたりする
ように要求しているかもしれません。
最も些細なやり取りを除くすべての場合、音声コマンドはメーカーのクラウド内の強力なコンピューターに中継され、そこで人工知能による重労働が行われます。コマンドが解析され、意味が抽出され、応答が準備されてスマート スピーカーに送り返されます。
機械学習は、私たちが対話する人工知能システムの大部分を支えています。これらの中には、スマート デバイスなどの家庭内のアイテムもあれば、オンラインで使用するサービスの一部もあります。 YouTube や Netflix の
おすすめ
ビデオと Spotify の自動プレイリストには機械学習が使用されています。検索エンジンは機械学習に依存しており、オンライン ショッピングは機械学習を使用して、閲覧履歴や購入履歴に基づいて購入の提案を提供します。
コンピューターは膨大なデータセットにアクセスできます。彼らは、人間が 1 回の反復を実行するのに必要なスペース内で、プロセスを何千回も精力的に繰り返すことができます (人間が 1 回でも実行できる場合)。したがって、学習に知識、実践、パフォーマンスのフィードバックが必要な場合は、コンピューターが最適な候補となるはずです。
だからといって、コンピューターが本当に人間の感覚で考えたり、私たちと同じように理解したり認識したりできるようになるというわけではありません。しかし、それは学び、練習することで上達します。機械学習システムを巧みにプログラムすれば、認識と意識のある存在の適切な印象を得ることができます。
私たちはよく「コンピューターは学習できるのか?」と疑問に思っていました。それは最終的に、より実践的な質問に変わりました。コンピューターに学習させるために克服しなければならない工学的な課題は何ですか?
ニューラル ネットワークとディープ ニューラル ネットワーク
動物の脳にはニューロンのネットワークが含まれています。ニューロンは、シナプスを介して他のニューロンに信号を発することができます。この小さな行動は何百万回も繰り返され、私たちの思考プロセスと記憶を生み出します。多くの単純な構成要素から、自然は意識と推論し記憶する能力を生み出しました。
生物学的なニューラル ネットワークにインスピレーションを得て、人工ニューラル ネットワークは、有機的なニューラル ネットワークの特徴の一部を模倣するために作成されました。 1940 年代以来、数千または数百万のノードを含むハードウェアとソフトウェアが開発されました。ノードはニューロンと同様に、他のノードから信号を受信します。また、他のノードに送信する信号を生成することもできます。ノードは、一度に多くのノードからの入力を受け入れたり、信号を送信したりできます。
ある動物が、飛んでいる黄色と黒の昆虫は常に自分にひどい刺し傷を与えると結論付けた場合、その動物は飛んでいる黄色と黒の昆虫をすべて避けるでしょう。ハナアブはこれを利用します。スズメバチのように黄色と黒ですが、刺し傷はありません。スズメバチに絡まれて痛い教訓を学んだ動物たちは、ハナアブにも広い余地を与えている。彼らは、印象的な配色で飛んでいる昆虫を見て、撤退する時が来たと判断しました。昆虫はホバリングできるが、スズメバチはホバリングできないという事実さえ考慮されていません。
飛び交う音、黄色と黒の縞模様の重要性は、他のすべてに優先します。これらの信号の重要性は、その情報の重み付けと呼ばれます。人工ニューラル ネットワークでも重み付けを使用できます。ノードは、その入力がすべて等しいと考える必要はありません。一部の信号が他の信号よりも優先される場合があります。
機械学習は統計を使用して、トレーニングの対象となるデータセット内のパターンを見つけます。データセットには、単語、数字、画像、Web サイトでのクリックなどのユーザー インタラクション、その他デジタル的にキャプチャして保存できるあらゆるものが含まれる場合があります。システムはクエリの重要な要素を特徴づけて、それらをデータセット内で検出したパターンと照合する必要があります。
花を識別しようとする場合は、茎の長さ、葉の大きさとスタイル、花びらの色と数などを知る必要があります。実際には、これらよりもさらに多くの事実が必要になりますが、簡単な例ではそれらを使用します。システムが試験片に関するこれらの詳細を認識すると、データセットから一致を生成する意思決定プロセスを開始します。印象的なのは、機械学習システム自体がデシジョン ツリーを作成することです。
機械学習システムは、アルゴリズムを更新して推論の欠陥を修正することで、間違いから学習します。最も洗練されたニューラル ネットワークはディープ ニューラル ネットワークです。概念的には、これらは、重なり合った非常に多くのニューラル ネットワークで構成されています。これにより、システムは意思決定プロセスで小さなパターンさえも検出して使用できるようになります。
通常、レイヤーは重み付けを行うために使用されます。いわゆる隠れ層は、「専門の」層として機能できます。これらは、被験者の 1 つの特性に関する重み付けされた信号を提供します。花の識別の例では、葉の形状、つぼみのサイズ、雄しべの長さ専用の隠れレイヤーを使用する可能性があります。
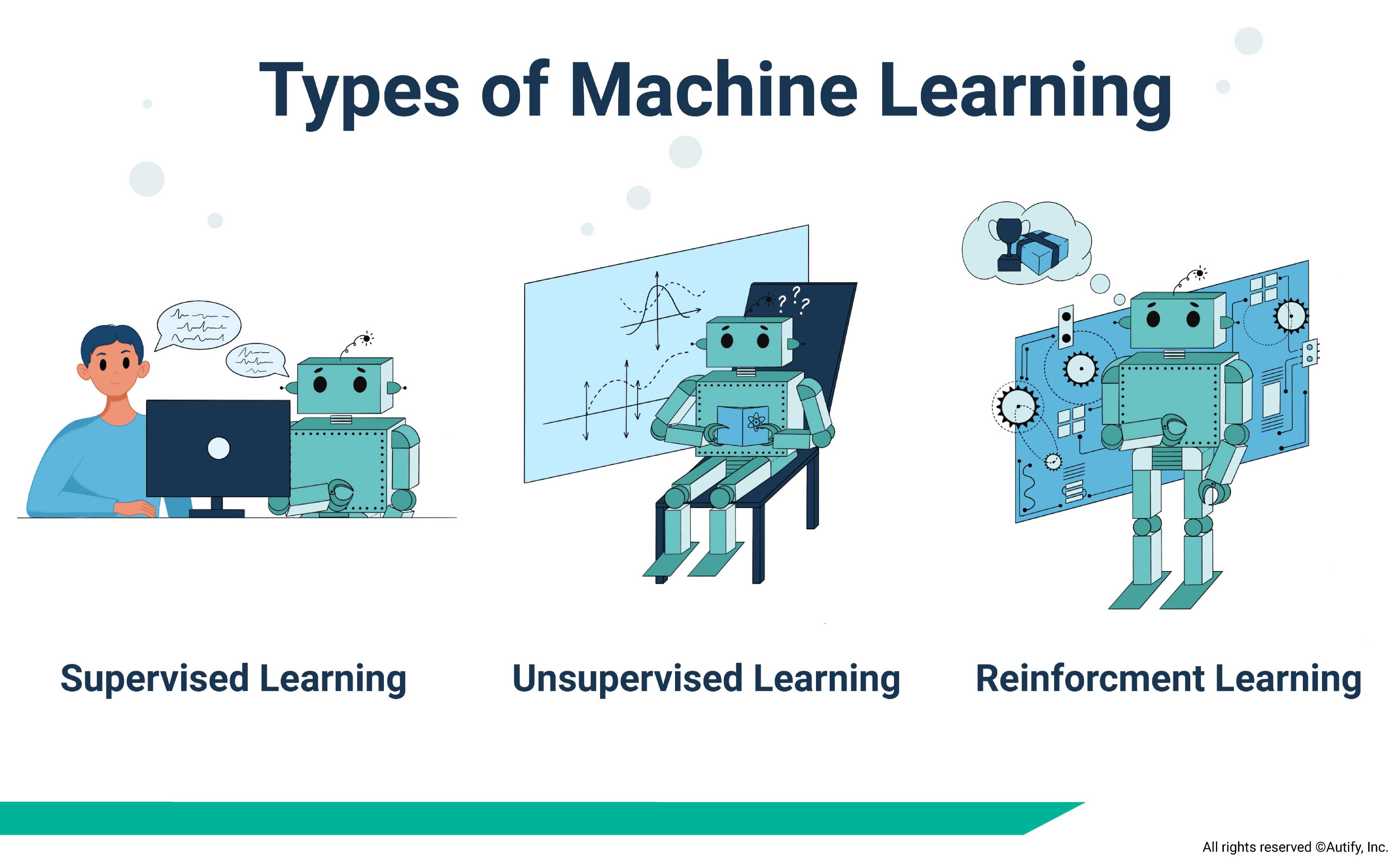
さまざまな種類の学習
機械学習システムのトレーニングには、教師あり学習、教師なし学習、強化学習という 3 つの広範な手法が使用されます。

教師あり学習
教師あり学習は、最も頻繁に使用される学習形式です。それは、それが本質的に他の技術より優れているからではありません。それは、現在作成されている機械学習システムで使用されるデータセットに対するこのタイプの学習の適合性とより関係があります。
教師あり学習では、意思決定プロセスで使用される基準が機械学習システムに対して定義されるように、データにラベルが付けられ、構造化されます。これは、YouTube プレイリストの提案の背後にある機械学習システムで使用される学習のタイプです。

教師なし学習
教師なし学習ではデータの準備は必要ありません。データにはラベルが付けられていません。システムはデータをスキャンし、独自のパターンを検出し、独自のトリガー基準を導き出します。
教師なし学習手法はサイバーセキュリティに適用され、高い成功率を誇っています。機械学習によって強化された侵入者検出システムは、以前に観察された許可されたユーザーの行動パターンと一致しないため、侵入者の不正なネットワーク活動を検出できます。

強化学習
強化学習は、3 つの手法の中で最も新しいものです。簡単に言えば、強化学習アルゴリズムは、試行錯誤とフィードバックを使用して、特定の目的を達成するための最適な動作モデルに到達します。
これには、システムの動作が目的の達成にプラスの影響を与えるかマイナスの影響を与えるかに応じて、システムの取り組みを「採点」する人間からのフィードバックが必要です。

AI の実践的な側面
機械学習は非常に普及しており、商業的な成功を含む現実世界での実証的な成功を収めているため、「人工知能の実用的な側面」と呼ばれています。これは大企業であり、機械学習を独自の開発や製品に組み込むことができるスケーラブルな商用フレームワークが数多くあります。
そのような強力な機能がすぐに必要ではないが、Python などの使いやすいプログラミング言語を使用して機械学習システムを試してみることに興味がある場合は、そのための優れた無料リソースもあります。実際、これらは、さらなる興味やビジネス上のニーズが生じた場合に合わせて拡張されます。
Torch は
、その速度で知られるオープンソースの機械学習フレームワークです。
Scikit-Learn は
、特に Python で使用する機械学習ツールのコレクションです。
Caffe は
深層学習フレームワークであり、特に画像処理に優れています。
Keras
は、Python インターフェイスを備えた深層学習フレームワークです。




