

AWS Personalize は、20 年以上のパーソナライゼーションの経験から構築された、Amazon.com で使用されているものとよく似た製品推奨エンジンです。これを独自の API として実装して、機械学習を使用してアプリの提案を強化することができます。
AWS パーソナライズとは何ですか?

「製品レコメンデーション エンジン」は、オンライン ショッピングだけでなく、さまざまなものに適用できる一般的な用語です。 YouTubeを例に考えてみましょう。新しい YouTube アカウントにサインアップすると、多くの視聴者にアピールする一般的なビデオ (主にトレンドになっているもの) が大量に入手できます。ただし、「minecraft letplay」を検索して 30 分のビデオを見ると、YouTube の推奨アルゴリズムがこれに注目します。ユーザーが気に入った動画のタグ、タイトル、チャンネル、投稿日、その他のメタデータを調べ、機械学習を使用して、その動画に似た、他のユーザーからの同様のエンゲージメントがあった他の動画を見つけようとします。 。人々は時系列順に物事を見る傾向があるため、同じシリーズからより多くのビデオを取得する可能性があります。おそらく、同様のコンテンツを作成している別のチャンネルがあり、それも気に入っているかもしれません。

これらはすべて機械学習の推奨事項によって強化されています。 「商品」とは何でも構いません。Amazon の場合、それは販売されている商品です。 YouTubeの場合は動画です。 Spotify にとって、再生するのは新しい曲です。 Facebook (実際には他のソーシャル メディア サービス) の場合、それはユーザーからの投稿です。

このエンジンはスタンドアロン PaaS にパッケージ化されており、特定の機械学習の知識は必要ありません。ユーザーのアクション (この投稿をクリックした、この曲を X 分間聞いたなど) をエンジンにフィードすると、エンジンは要求に応じて製品カタログから新しい推奨事項を吐き出します。推奨事項は最初は少しむらがあるかもしれませんが、モデルが十分にトレーニングされると、非常に正確になり始めます。
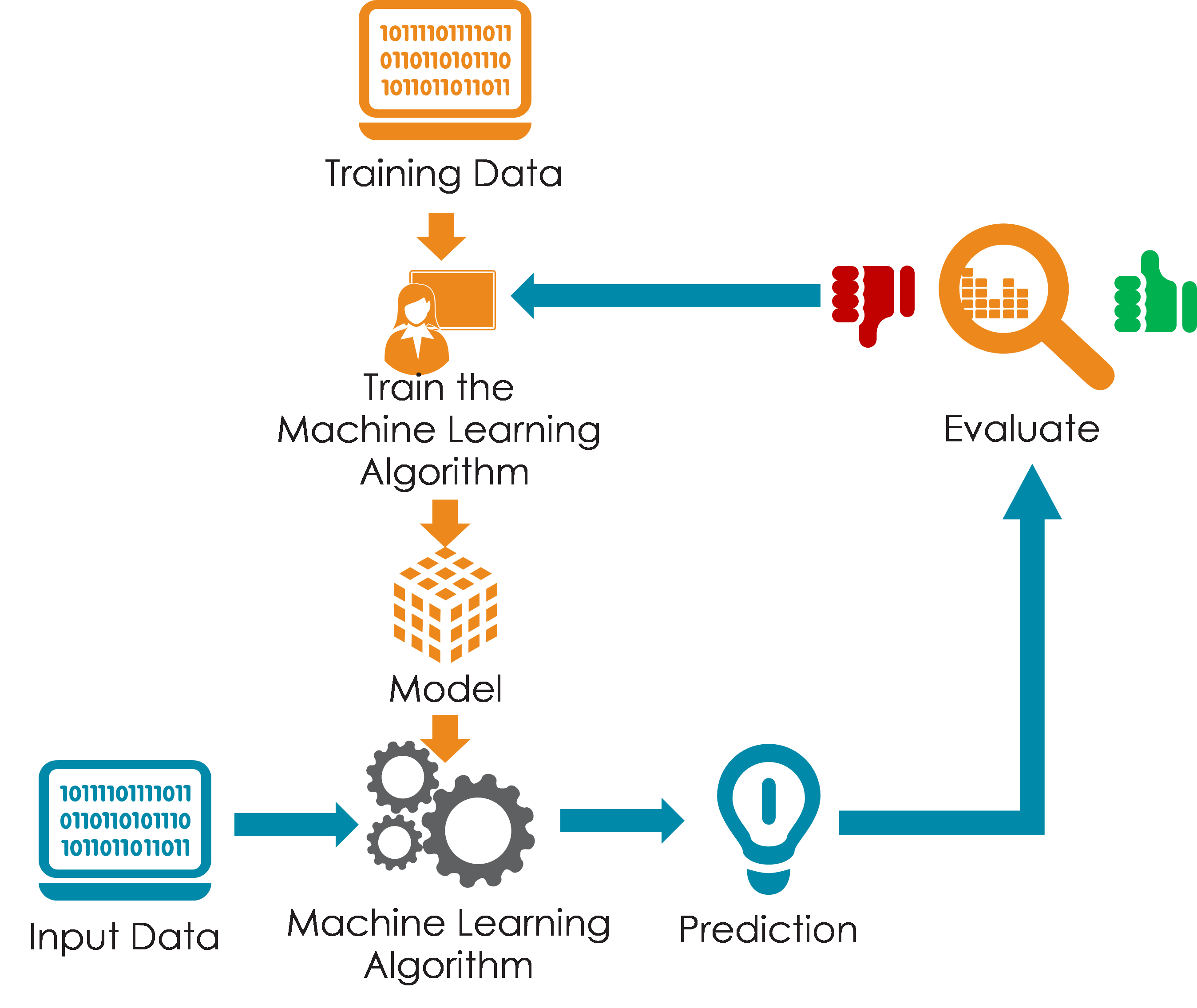
AWS Personalize のセットアップ

各
AWS Personalize
プロジェクトには 3 つのデータセットがあります。
- ユーザー: ユーザー自身に関するメタデータを追跡します。
- 商品カタログとして機能するアイテム
- インタラクション: ユーザーとアイテムの間のインタラクション イベントを記録します。
インタラクション リストは、すべてのイベントを追跡し、モデルのトレーニングの基礎として機能するため、最も重要です。ユーザーとアイテムのリストは、モデルがインテリジェントな接続を確立するのに役立つ補足データを提供します。たとえば、Personalize はユーザーの年齢を知っているため、該当する可能性に基づいて、さまざまな年齢グループにさまざまな製品を推奨できます。
デフォルトのオプションでは、CSV ファイルから履歴データをインポートしますが、すべての作業が完了したら、Event Tracker API を使用してリアルタイムの更新を送信することもできます。ただし、インポートするにはトレーニング データが必要です。インタラクション リストのエントリが 1,000 未満の場合、インポートは失敗します。 Personalize をテストしたいだけの場合は、インポートを続行する前に、スキーマに準拠する何らかのダミー データを作成する必要があります。
開始するには、
AWS Personalize マネジメントコンソール
にアクセスしてください。個別の「アプリ」として機能する新しいデータセット グループを作成します。名前を尋ねられます:
「次へ」をクリックすると、インタラクションのインポートを構成する画面が自動的に表示されます。名前 (「interactions」) を付け、スキーマを定義します。これは
Apache Avro
形式であり、各インタラクション (または製品/ユーザー) にどのようなフィールドがあるかを Personalize に指示します。インタラクションの場合、最も基本的なのは USER_ID と PRODUCT_ID のバインドです。これは、他のテーブル (多対多のリレーショナル リンク) からユーザーと製品を検索するために使用されます。
次に、S3 の CSV ファイルから Personalize にデータをインポートする必要があります。まず、このバケットにアクセスできるサービス ロールを選択または作成します。また、Personalize によるアクセスを許可するには、次のバケット ポリシーをターゲット バケットにアタッチする必要があります。
bucketname
バケットの名前を付けたもの:
{
“バージョン”: “2012-10-17”,
“ID”: “PersonalizeS3BucketAccessPolicy”,
“声明”: [
{
“Sid”: “PersonalizeS3BucketAccessPolicy”,
“効果”: “許可”、
“主要”: {
「サービス」: 「personalize.amazonaws.com」
}、
“アクション”: [
“s3:GetObject”,
「s3:リストバケット」
]、
“リソース”: [
“arn:aws:s3:::バケット名”,
「arn:aws:s3:::バケット名/*」
】
}
】
}
次に、ファイルへのパスを貼り付けます。
[完了] をクリックすると、データセット パネルが表示され、インタラクション データセットが構成されたことがわかります。このプロセスをさらに 2 回繰り返して、ユーザーと製品のデータセットを作成する必要があります。データのサイズによっては、すべてをインポートするのにおそらく数分かかります。
すべてをインポートしたら、データに基づいてトレーニングされたモデルであるソリューションを作成する必要があります。これは、実際の推奨事項を提供するキャンペーンの基礎として使用できます。ダッシュボードから作成します。
名前を付け、ソリューションを強化するために使用するレシピを選択します。これを手動で選択することも、AWS の HRNN を使用して予測を行う「AutoML」を選択することもできます。よくわからない場合は、AutoML を選択してください。
ソリューションには管理を容易にするために複数のバージョンが含まれます。ソリューションを作成すると、初期バージョンも作成されます。
ソリューション バージョンの初期化が完了したら、キャンペーン (基本的に、実際の推奨事項を取得するためのインスタンス化された推論エンジン) を作成できます。アプリケーションからクエリして使用できる REST API エンドポイントがあります。
サイドバーの「キャンペーン」タブから、新しいキャンペーンを作成し、名前を付けて、ソリューションを選択します。作成したら、AWS CLI からテストできるようになります。
aws Personalize-rec get-recommendations --campaign-arn $CAMPAIGN_ARN
–user-id $USER_ID –query “itemList[*].itemId”
このコマンドは、指定されたユーザー ID のキャンペーンから推奨事項を取得します。すべてが正しく動作すると、ユーザーに推奨されるアイテム ID のリストが表示されます。
リアルタイム データをソリューションに追加するには、サイドバーからイベント トラッカーを作成する必要があります。これにより、データの入力に使用できるトラッカー ID が得られます。
これを設定するには 2 つの方法があります。AWS のウェブおよびモバイルアプリのバックエンド フレームワークである AWS Amplify を使用している場合、セットアップは簡単で、Amplify コンソールから設定するだけです。そうでない場合は、Lambda 関数を設定してデータを処理し、Personalize に送信する必要があります。




