

重要なポイント
- マルチモーダル AI は、複数の入力ソース (テキスト、画像、音声、センサー) を使用して、より良い結果とより高度なアプリケーションを実現します。
- マルチモーダル AI は知識が豊富で、さまざまな入力を関連付けて、強化された結果を提供できます。
- マルチモーダル AI モデルの例には、Google Gemini、OpenAI の GPT-4V、Runway Gen-2、Meta ImageBind などがあります。

初期の AI モデルは、テキスト プロンプトを解釈する能力に基づいて優れた印象を与えましたが、マルチモーダル AI はそれ以上の能力を備えています。既存のモデルがより多くの入力モダリティを受け入れるように拡張されるにつれて、AI ツールはさらに高度になる一方です。
「マルチモーダル」とはどういう意味ですか?

「マルチモーダル」という言葉は文字通り複数のモードの使用を指し、AI の文脈では、トレーニングとより多くの情報に基づいた結果を得るために異なる入力ソースを使用することを意味します。 2023 年に世界を席巻したチャットボットは、テキストという 1 つの入力モードしかサポートしていませんでした。
マルチモーダル AI は 2 つ以上の入力方法を受け入れることができます。これは、モデルをトレーニングするときとモデルを操作するときの両方に当てはまります。たとえば、画像データセットと音声データセットの両方を使用して、特定の画像を特定の音声に関連付けるようにモデルをトレーニングできます。同時に、テキストの説明と音声ファイルを組み合わせて、両方を表す画像を生成するようにモデルに依頼することもできます。
考えられる入力モードには、テキスト、画像、音声、または温度、圧力、深度などのセンサーからの情報が含まれます。これらのモードはモデル内で優先順位を付け、意図した結果に基づいて結果に重み付けを行うことができます。
マルチモーダル モデルは、2023 年に人気が爆発したユニモーダル モデルの進化版です。ユニモーダル モデルは、単一の入力 (テキストなど) からのみプロンプトを取得できます。マルチモーダル モデルでは、説明、画像、音声ファイルなどの複数の入力を組み合わせて、より高度な結果を提供できます。
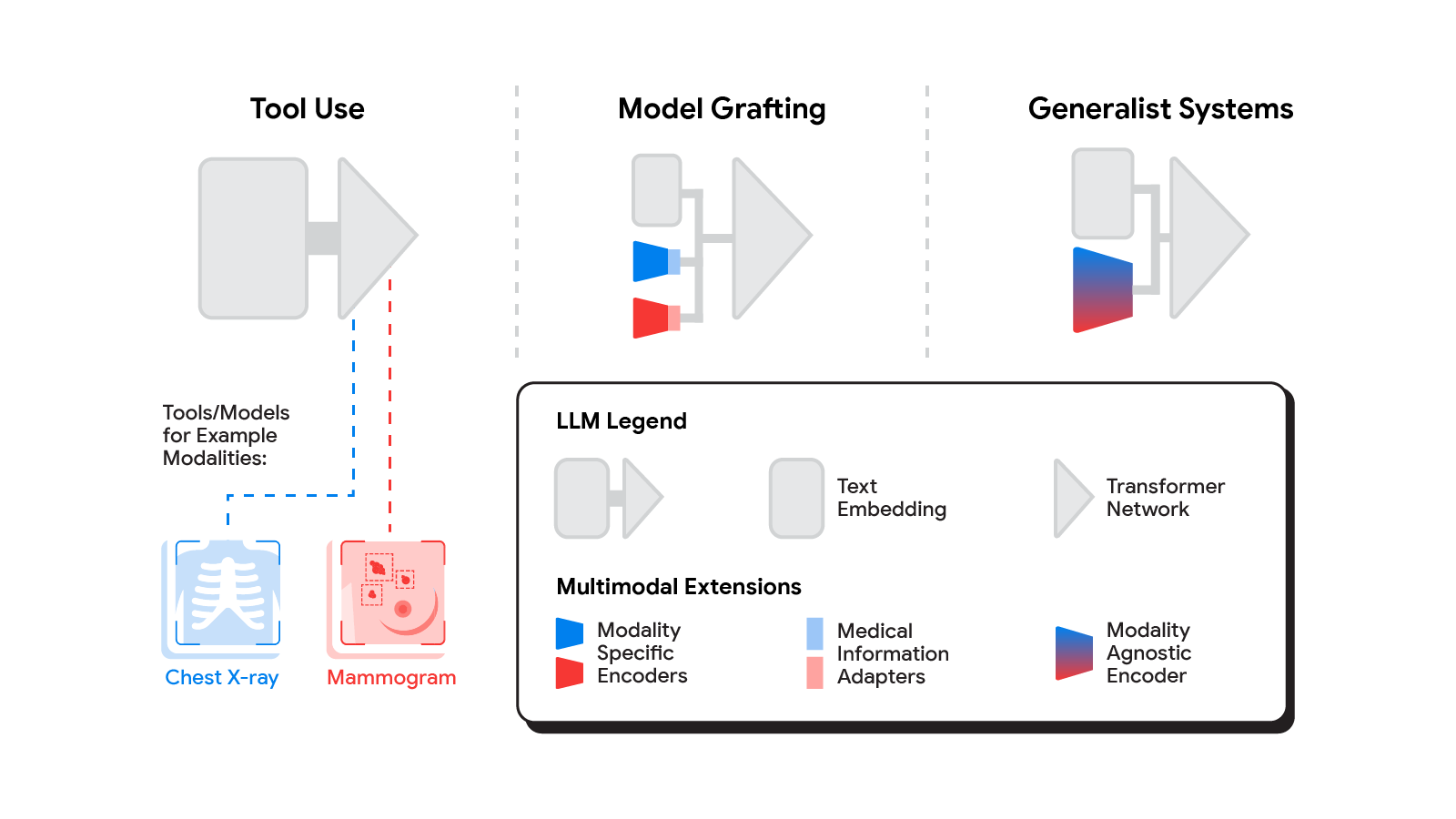
マルチモーダル AI は通常の AI よりどのように優れているのでしょうか?
マルチモーダル AI は、現在の AI モデルを論理的に進化させたもので、より「知識が豊富な」モデルを可能にします。これらのモデルの用途は、消費者向けの使用、機械学習、業界固有の実装の両方の点ではるかに広範囲です。
撮影した写真に基づいて新しい画像を作成したいとします。写真を AI にフィードして、見たい変化を説明することができます。音を特定の種類の画像に関連付けたり、温度などの関連付けを描画したりするようにモデルをトレーニングすることもできます。このようなタイプのモデルは、テキスト上でのみ対話している場合でも、「より良い」結果が得られます。
他の例には、音声とビデオの両方を使用してビデオにキャプションを付け、画面上で起こっていることとテキストを同期したり、結果を強化するためにグラフやインフォグラフィックを使用してより適切な情報を収集したりすることが含まれます。もちろん、 チャットボットと会話するときは、常に健全なレベルの懐疑心を維持する 必要があります。
マルチモーダル AI は徐々に日常のテクノロジーに浸透してきています。モバイル アシスタントは、より多くのデータ ポイントを持ち、より適切な仮定を立てるためのコンテキストが追加されるため、マルチモーダル モデルを使用すると大幅に改善される可能性があります。スマートフォンには、カメラ、マイク、光センサーと深度センサー、ジャイロスコープと加速度センサー、地理位置情報サービス、インターネット接続がすでに搭載されています。これらはすべて、適切な状況でアシスタントにとって役立つ可能性があります。
業界への影響は計り知れません。より適切な判断ができるように、複数の入力を使用してある種のメンテナンス タスクを実行するようにモデルをトレーニングすることを想像してください。コンポーネントが熱くなっていますか?コンポーネントが磨耗しているように見えますか?必要以上に音が大きくありませんか?これをコンポーネントの古さや平均寿命などの基本情報と組み合わせることができ、入力値に重みを付けて合理的な結論を導き出すことができます。
マルチモーダル AI の例
Google Gemini は おそらく、マルチモーダル AI の最もよく知られた例の 1 つです。このモデルには論争がないわけではなく、2023年後半に リリースされたモデルをデモするビデオは 中傷者によって「偽物」の烙印を押された。 Googleは、ビデオが編集されたこと、結果が静止画像に基づいておりリアルタイムで行われたものではないこと、プロンプトが音声ではなくテキストで提供されたこと を認めた 。
開発者は、Google AI Studio で API キーを申請する だけで、今日から Gemini の使用を開始できます。このサービスは、1 分あたり最大 60 クエリの制限を持つ「誰でも無料」レベルで開始されました。サービスを設定するには、Python をしっかりと理解する必要があります (始めるための 優れたチュートリアルはこちらです )。
とはいえ、Gemini は、さまざまな言語の音声、画像、ビデオ、コード、テキストでトレーニングされた、依然として有望なマルチモーダル AI モデルです。これは、テキストと画像の両方のプロンプトを受け入れることができる OpenAI の GPT-4 と対戦します。 GPT-4V (V はビジョンを表す) としても知られるこのモデルは、 ChatGPT Plus ユーザーが OpenAI Web サイト 、モバイル アプリ、API 経由で利用できます。
GPT-4V を Bing Chat 経由で無料で使用して、デバイスのカメラや Web カメラから画像をアップロードしたり、写真をスナップしたりできます。 「何でも聞いてください…」ボックスの画像アイコンをクリックするだけで、クエリに画像を添付できます。
他のマルチモーダル モデルには、テキスト プロンプト、画像、既存のビデオに基づいてビデオを生成するモデルである Runway Gen-2 が含まれます。現時点では、結果は 非常に AI によって生成されたように見えますが、概念実証としては、まだ興味深いツールです。
Meta ImageBind は、テキスト、画像、オーディオに加えて、ヒート マップ、深度情報、および慣性を受け入れるもう 1 つのマルチモーダル モデルです。 ImageBind Web サイトの 例 をチェックして、より興味深い結果を確認する価値があります (水を注ぐ音声とリンゴの写真を組み合わせて、シンクで洗っているリンゴの画像を作成する方法など)。
マルチモーダル AI モデルの採用は、このテクノロジーについてすでに聞き飽きている人にとっては悪いニュースであり、OpenAI のような企業はしばらくの間、ニュースにさらされることになるでしょう。しかし本当の話は、Apple、Google、Samsung、その他の大手企業がどのようにしてこのテクノロジーを家庭に、そして消費者の手のひらに持ち込むかということです。
結局のところ、メリットを享受するために、別の AI バズワードと対話していることを意識する必要はありません。そして家庭用電化製品以外では、医学研究、医薬品開発、疾病予防、工学などの分野の可能性が最も大きな影響を与える可能性があります。




